
Второе из серии эссе об устройстве нейросетей и грамотном общении с ними. Первое – здесь.
Вам нужен агент, который возьмет на себя черную работу. Чтобы навайбкодить такой агент, необязательно быть айтишником.
Нужен в первую очередь здравый смысл.
Здесь я как практикующий промпт-инженер объясню, как не дать агенту потратить столько денег заказчика, что его продукт уже того не стоит. Все сводится к счетам, которые провайдер ИИ (Claude, GPT, Gemini и др.) выставляет вам за токены.
Каждый токен — это символ или группа символов, на которые делит любой текст программа-токенизатор. На обложке я специально привел для бунинского текста реальные токены с их цифровыми идентификаторами. Как видите, один и тот же токен может входить в состав самых разных слов. Для большой языковой модели токены не несут никакого смысла.
Цифровой идентификатор — это номер определенного набора координат в пространстве мышления. Ваш мир — всего четыре измерения: длина, ширина, высота и продолжительность во времени. В пространстве мышления уже более 12 288 измерений. Получив от вас текст (контекст и промпт), модель помещает его токены в пространство мышления и считает, насколько все они близки друг к другу и какие токены лучше всего с ними сочетаются.
Больше всего пространство мышления похоже на музыку. Так и ноты сами по себе ничего не значат. Но из них собираются сочетания — аккорды разной благозвучности. Между аккордами в музыкальном пространстве тоже свои отношения. Композитор берет аккорд-тонику, уводит музыку к субдоминанте, нагнетает напряжение через доминанту и, наконец, триумфально разрешает обратно в тонику. Пока исполнитель до тоники не дойдет, слушателю покоя не будет. Именно так языковая модель генерирует текст, приводя его от неустойчивых токенов-доминант к устойчивым тоникам конца фразы.
Вы семь лет страдали в музыкальной школе, так и не став музыкантом? До сих пор спрашиваете себя, за что вам такое несчастье? Могу порадовать, у вас как у промпт-инженера большое конкурентное преимущество передо мной. Чтобы лучше понимать модели LLM, я часами слушаю фортепианную классику и тяжёлый металл, учусь читать ноты, а у вас эта база с детства.
Откуда берутся такие безумные счета за токены?
Каждая новая модель — все более искусный исполнитель. Но разные модели не могут одинаково хорошо выполнять все задачи. У них разные токенизаторы и пространства мышления.
Для сравнения: Евгений Кисин способен хорошо сыграть джаз, а Диана Кролл — пьесу Шумана, но все-таки лучше, когда наоборот. Что между ними общего? Пригласить их поиграть у себя дома не каждому по карману.
Так и с флагманскими моделями. Как только выходит новая модель Claude или GPT, ее пробуют и пишут посты вроде: «Какая же она классная! Мой агент с ней просто летает, он перестроил архитектуру проекта и нашёл в коде дыру, о которой мы не подозревали. Вот только за 15 минут модель съела пятичасовой лимит моих токенов! Придется докупить.»
Это первый звонок. Уже сейчас AI-агенты, которые пишут код, порой обходятся дороже людей-разработчиков. Такими темпами в следующем году затраты на ИИ в работе над особо сложными задачами может превысить стоимость человеческого труда:
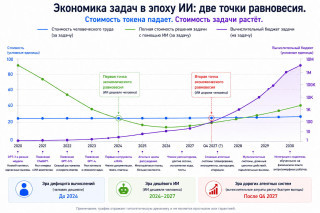
А как же сингулярность и восстание машин? Да нам бы промпты написать так, чтобы по миру не пойти. Если мы возьмемся за ум, расходы на ИИ не полезут в гору так резко, как на моем графике. Давайте поговорим о вещах практических.
Технически труд пианиста состоит из трех процессов:
- прочитать ноты;
- сопоставить их с отработанными рефлексами;
- извлечь звук на инструменте.
Все это без ошибок и выразительно. За эти навыки платят музыканту.
Модель обрабатывает:
- токены контекста и промпта, которые мы в нее ввели;
- промежуточные токены, которые участвуют в сопоставлении запроса и будущего ответа;
- токены ответа.
На каждый токен расходуется электроэнергия и ресурс видеопроцессора. За них мы и платим.
Формулировкой промпта можно повлиять на первые две стадии. Условно говоря, написать хорошие ноты настолько ясно, чтобы исполнитель все верно понял, сопоставил и мог сыграть с выражением.
Если агент за полчаса палит месячный лимит, значит, скорее всего, промпты написаны плохо. Одно из трех:
- Модель с трудом продирается через нагромождение слов и делает что-то лишнее. Умная флагманская LLM видит, что получается ерунда. Выбиваясь из сил, она кружится, генерирует километры рассуждений, вызывает десятки своих инструментов, которые все равно не помогут. Колоссальных размеров записи «рассуждений вслух» сжирают бюджет.
- Рассуждающая модель вроде Gemini Flash Thinking организует себе контроль качества, который философски называется «внутренний цикл саморефлексии». Если самопроверка признает результат генерации неудачным, все проходит заново с тем же промптом. Так случается, если модель верно понимает промпт, но через раз.
- Всё прекрасно работает, генерируется вполне качественно, только выходит совсем не то, чего хотел заказчик. Он принимается материть несчастного агента в чате Cowork (Codex, Antigravity). Валидол — антидепрессанты — алкоголь — бессонная ночь — перегенерация. Опять лишние токены.
Очень похоже на строительство по некачественному проекту:

Что нужно знать, чтобы модель вас правильно понимала?
Токенизация — это судьба
Интуитивно кажется так: чтобы тебя правильно понимали, выбирай как следует слова. Три года назад я так и делал по-редакторски. Переписывал промпты грамотно хорошим языком, понятным человеку. Это совсем не работало на русском, чуть лучше обстояло дело с английским. Наш промптинг был похож на взлом сейфов перебором цифр кода. Попробуй это слово. Работает? Нет! Давай другое. Безо всякой системы.
Но это уже в прошлом. Написание промптов превратилось в науку.
Если в 2025 году ежемесячно появлялась на arxiv.org новая статья, менявшая наш подход, то сейчас таких публикаций уже три в месяц. В декабре 2025 года группа индийских ученых в работе Broken Words, Broken Performance: Effect of Tokenization onPerformance of LLMs оценила количественно влияние токенизации на вероятность попадания в правильный по смыслу ответ.
Суть вот в чем мы в уме делим слово на его естественные части (корни, суффиксы, приставки): «не-пре-мен-но», или вовсе не делим: «борщ». У LLM иной подход. Чтобы она могла вычислять следующий токен эффективно, токенов не должно быть слишком много. Иначе у модели «разбегаются глаза»
Только для генерации на каком-нибудь одном языке токенов уже более 100 тысяч. Главное не плодить лишние токены, чтобы сэкономить электричество. А понимать токенизатор ничего не должен. Он делит слова на сочетания символов, которые встречаются чаще всего. Получается «неп-ременно» и «бор-щ». Если токен совпадает со словом, как например «француз», то больше вероятность, что модель найдет в обучающих данных правильные ассоциации.
Вместо «непременно» лучше выбрать «обязательно», поскольку от него токенизатор отделяет естественную приставку: «об-язательно». Но так дело обстоит именно с GPT. У моделей от Anthropic или Google может быть совсем наоборот. Вот почему один ИИ хорошо понимает ваш промпт, а другой на нем же спотыкается.
Конечно, флагманская рассуждающая модель GPT-5.5 в уме все такие «непременно» собирает как надо при каждом исполнении промпта. Но на размышления уходят токены, то есть ваши деньги. Если надо в чате сгенерировать один текст, это пустяки. А если агент читает сотни тысяч текстов и всё с тем же промптом, открывайте капот и смотрите на токены.
Ключевые инструкции лучше писать по-английски. Там самые распространенные короткие слова чаще совпадают с токенами. Наверняка вы замечали, что рассуждающие модели свои промежуточные размышления показывают на английском. Это недаром так.
Не надо говорить с моделями образно и красиво. Зачем вам »jubilant» («ликующий») из двух токенов «jub» + «ilant», когда есть «happy», «счастливый»? А «happy» для LLM — знакомый цельный объект с богатыми ассоциациями из обучающих данных.
И конечно, избегайте составных конструкций с дефисами. По дефису они делятся на разные слова, порой с противоположными значениями. Скажем, «cost-effective», экономически эффективный, буквально «эффективный по цене». Развалится в руках модели на три токена: цена, дефис и эффективный. А цена-то ниже там, где эффективность выше. Так это слово, хорошо действующее на воображение, заставляет модель тратить ресурсы внимания на увязку цены с эффективностью. Того же самого вы добьётесь простым незатейливым токеном »cheap», «дешевый».
Провайдеры ИИ открывают свои токенизаторы для подписчиков, чтобы промпт-инженеры могли получше выбирать слова. Цена вопроса — до 10% точности: выбор конкретных синонимов влияет на качество и стоимость генерации так же, как структура промпта и заложенные в нем рассуждения.
Но вот наконец под капотом всё чудесно и промпт хороший. А ваш агент продолжает жечь токены, как реактивный двигатель. Потому что промпту предшествует огромный контекст. Допустим, агент занимается недвижимостью. В нем два скилла (управляемых промптами навыка):
- обойди сайты, на которых продают французскую недвижимость, собери все объявления о Париже и положи как текстовый файл в такую-то папку;
- в собранных первым скиллом объявлениях найди квартиру в хорошем районе, не выше 5 этажа и не дороже 800 тысяч евро.
Не пытайтесь повторить это у себя дома! С такими промптами поиск недвижимости обходится дороже самой недвижимости. Первый промпт наберет гору текста, пропустив его через себя, а второй закинет эту гору в свою пасть, — и весь этот банкет за ваш счет.
А главное, не проверишь, всё ли они нашли в этих объявлениях. Дешевые модели найдут меньше, дорогие больше, но какой у них реально КПД и что они делают, не поймешь.
Даже выйдя в прибыль, вы не узнаете, какая у вас маржа и насколько оправданы издержки.
Как стать миллионером? Мнение миллионера
Во второй половине XIX века большинством московских магазинов владел купец Гаврила Солодовников (1826-1901). Он богател с поразительной скоростью. Это был гений оптимизации расходов. Обедал вчерашней гречкой, жил в развалюхе. На его коляске шины были только у задних колёс, где восседал сам Гаврила Гаврилович. А передние колёса — с железными ободами: там кучер, «он и так поездит». Капитал Солодовникова превышал 20 млн рублей. Если отсчитать их николаевскими десятирублевками, получится около 15,5 тонны чистого золота. По ценам лета 2026 года это больше 2 млрд долларов.
На вопрос коллег, как это у него получается, Солодовников показывал обычную тетрадку и говорил:
Вот вся моя бухгалтерия. Если хотите богатеть, не держите бухгалтеров и канцелярий. Все ваше дело должно быть в вашей голове. Не следует заводить дело больше того, что вмещает ваша голова.
Он представлял себе действия каждого своего сотрудника и движение каждой копейки.
Так вот, ИИ-агент — это ваше предприятие, где сотрудники — это промпты, а копейки — токены.
Про каждого сотрудника нужно знать:
- что он делает?
- насколько эффективно тратит ваши ресурсы?
- можно ли заменить его роботом?
Да, для модели LLM робот – это программа. Скрипт, который выполняет ее работу не за токены. Представьте себе агент-аэропорт. Можно поручить умной модели собрать пассажиров на рейс в Гамбург. Промпт: «Обеги весь аэропорт, спроси каждого пассажира, в Гамбург ли он летит, зарегистрируй всех, кто в Гамбург, и отведи в самолет». Обычная LLM или не успеет всех зарегистрировать, или найдет не всех. Флагманская модель Claude Fable 5 – чемпион мира в спринте. Она обежит весь гигантский аэропорт, всех опросит, нужных зарегистрирует, в самолет отведет. И возьмет с вас по часовой ставке действующих чемпионов мира.
А как надо? Все уже придумано. В нормальном аэропорту квалифицированные промпты нужны только там, где принимаются решения. Они опрашивают пассажиров при регистрации, выдавая им посадочные талоны. А почти бесплатные скрипты выводят на табло приглашение к нужному гейту и просто пускают в самолет всех, у кого правильный талон. За спиной у них могут стоять простенькие промпты, проверяющие талоны еще раз.

Не надо быть программистом, чтобы создавать такие скрипты. Модели отлично пишут их на языке Python. Стоит проверить на парочке примеров, делает ли скрипт именно то, что вам нужно. Информацию хранят в объектах JSON как пары «ключ: значение». Вам остаётся только назвать нужные вам ключи.
В случае с Парижем первый промпт читает объявления и каждому дает такой посадочный талон, выбирая из возможных значений выбранных вами ключей. Вы должны обеспечить его информацией, чтобы он сделал правильный выбор среди значений такого JSON:

Получается компактная карточка объекта с выделенной «ДНК» квартиры, которую собрал ваш промпт № 1. С этого момента вы не скармливаете нейросети мегабайты объявлений. На сцену выходит короткий дешевый промпт № 2. Его задача — просто поговорить с пользователем.
Он выслушает ваше человеческое: «найди мне квартиру в хорошем районе, не выше 5 этажа и не дороже 800 тысяч», вытащит из этой фразы три параметра, сам вызовет Python-скрипт и даст ему точное задание. А этот бесплатный скрипт за секунды отберет из базы готовых JSON-файлов нужные объекты. Модель не делает грязную работу, не таскает мешками токены, а лишь координирует процесс, сохраняя ваши деньги:
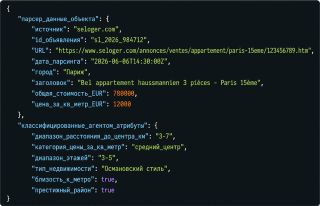
Примечание: в обоих JSON по недвижимости ключи показаны по-русски только для простоты восприятия. Мы уже говорили о преимуществах англоязычных токенов. В реальных боевых JSON ключи только на английском.
Зачем Шекспир придумал могильщиков?
Когда я только входил в профессию промпт-инженера, мне казалось, что это почти писательство. Твой текст умная модель читает и делает все, как ты сказал. А оказалось, промпт-инженер ведет себя скорее как режиссер, который ставит задачу актерам. От него требуется говорить не красноречиво, а просто и доходчиво. Не чтобы его слушали, развесив уши, а чтобы делали ровно то, что он сказал. А модели ведут себя со мной как актеры.
Самый хороший актер может заболеть, забыть слова или поступить назло режиссеру, демонстрируя своё прочтение роли (контекста). С промптами то же самое. 300 спектаклей подряд модель в ударе, а на 301-й вдруг запой, жена ушла, собака сдохла, сахар упал. К счастью, пользователь обычно этого не видит, потому что я ставлю за спиной каждого промпта маленький промптик-контролер. Который проверяет исполнение роли и возвращает своенравному артисту его аутпут, чтобы тот вовремя переделал.
Образуется целая банда промптов, которой кто-то должен управлять.
Начинающие пишут скилл как такой обер-промпт. «Начни разговор — позови промпт №1 — вызови скрипт № 2 — проверь выдачу — позови промпт № 3». Этакий главный актер, ведущий спектакль. Говорят, так Евгений Евстигнеев царил на съемочной площадке фильма «Собачье сердце» в образе профессора Преображенского. Задавал актерам такую планку, что они выложились каждый на пределе возможностей. Да, флагманская модель на такое способна. Но это слишком дорогое удовольствие.
Театры давно научились считать деньги и передали эту функцию помощнику режиссера, чей труд стоит совсем недорого. Он работает не за процент со сбора, а за фиксированную скромную зарплату. Стоит в кулисах и говорит, когда чей выход, а также проверяет, что все идет по плану. Хотя его не видать и не слыхать, на нем все держится.
Для вашего агента лучше всего написать простой скрипт, который обычно называется pipeline.py. Он своей железной рукой гарантированно позовет промпты со скриптами и контролерами, так что будет сделано все заложенное в скрипте.
Ещё одна идея, позаимствованная в театре, — поручать более простые промпты (роли) более дешевым моделям. Ради кассы и экономии театральные предприниматели времен Шекспира заполнили сцену второстепенными персонажами. Следить за таким разнообразным действом гораздо интереснее, чем за древнегреческими спектаклями, где на виду только пара главных героев и хор. А стоят актеры второго плана куда меньше, чем герой-любовник.
На картинке я показал, как первые роли поручают более дорогим моделям. У Claude это семейство Opus. Характерные роли могут исполнять модели сильные, но односторонние, как Sonnet. А с простыми вроде «кушать подано» справятся наиболее дешевые Haiku. И всеми движет помощник режиссера pipeline.py, ваш верный скрипт:

Вот зачем Шекспиру понадобились могильщики в «Гамлете»! Чтобы пристроить пожилых актеров, которые когда-то были героями-любовниками. А сейчас они острят про покойников. Зажигательно, только за куда более скромную плату.
Запуская простенькую дешевую модель для промпта-контролера, подумайте о быстротечности времен. Вроде бы совсем недавно была она самой передовой, и ютуберы в своих обзорах неделями говорили только о ней. Какие она берет бенчмарки, что за фурор она вызвала в профессиональном сообществе, да как перевернула представление об ИИ-ассистентах, и будто бы сам Юваль Харари всерьез опасается, что с нее начнется восстание машин.
А теперь она стоит на заднем плане, подбирает оброненный новым флагманом аргумент и скромно предлагает управляющему скрипту передать этот аргумент еще раз.
***
Ну что за пафос? Шекспиру могильщики нужны, чтобы в ключевой сцене накал пафоса сбивать. Отсюда Гамлет пойдет на почти верную смерть. Ну кто поверит, что так бывает, если он станет снова читать «Быть или не быть?» А под шуточки с черепом бедного Йорика его решение выглядит естественно.
Так ведь этот бедный Йорик — результат безошибочного математического расчета.
Как Шекспир занимался математикой и где промпт-инженеры используют его приемы, поговорим в следующем выпуске.




